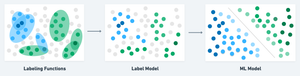
Introduction
Behind every good ML model, there is a good dataset. This shouldn’t come as a surprise to anybody—after all, the entire premise of “machine learning” is based on developing methods that “learn” how to perform some task by understanding examples—data—related to that task. Even so, because collecting/assembling the data to use for training a model is usually the least enjoyable aspect of constructing an ML solution (often requiring people to spend tens if not hundreds of hours on labelling by hand for supervised datasets), the dataset construction step is often either overlooked, or it costs dedicated workers hours of their lives working on laboriously labelling data. Having a lot of data is often a good thing, but it also increases the difficulty of ensuring both fairness in the data itself, as well as the quality and consistency of the labels.
For BetterUp’s machine learning and data teams, the problem of determining how to effectively make use of such large, unlabelled datasets is one of the biggest challenges we have to overcome, as we work toward our ultimate goal which isn’t about the data at all—it's about transforming people to live their lives with greater clarity, purpose, and passion. Data is one powerful lever we can pull toward achieving that goal; depending on the task, there are a number of ways we might approach labeling vast amounts of data, such as generating pseudo-labels with self-supervision or zero-shot learning, or even generating synthetic data itself. While those might be the subject of a future article, today we’re excited to share a battle-tested technique we use known as weak supervision.
What is Weak Supervision?
Imagine that someone, presumably in management, has handed you a corpus of documents containing ten thousand sentences and told you that you need to develop a high-quality text classifier by Friday. It’s Wednesday afternoon, and the clock is ticking. You know the task is to train a model to distinguish between two types of writing styles, “Slang” and “Shakespearean”, but your corpus is wholly unlabeled. How are you going to train a model/classifier in such a short amount of time? As you begin to dive into the data, you do see the differences in style. Some sentences look like this:
- “Pizza Hut goes hard, no cap”
- “This is what no sleep does to a [expletive]”
- “Learning languages is a beautiful art 🥲❤”
while others are more like this:
- “Let me not to the marriage of true minds”
- “And thy best graces spent it at thy will!”
- “I say again, hath made a gross revolt”
Clearly, there’s a significant distinction here. But you’re running out of time, and you don’t have the resources to apply this thinking to the 10,000 sentences you’ve been given. Or do you?
You make a few key observations:
- Modern slang has quite a few special words/characters (emojis, expletives, abbreviations [think “lol”, “lmao”, “tbh”, and so on)
- Shakespearean English also has quite a few special words/characters (“thy”, “hath”, “'twas”) but perhaps more so, the grammar feels somehow distinct from the way we use English today, although you can’t quite pin down exactly how.
Based on these observations, you create some simple functions that programmatically apply labels to sentences. For example, by using your favorite NLP library like spaCy to scan for particular keywords or to decompose the text into more fundamental linguistic forms (i.e. classifying words into nouns, verbs, adjectives/adverbs, prepositions and so on) in which you can match specific lexical patterns. Using these rule-based classifiers, you can quickly apply labels in a simple and systematic fashion. After a few hours of coding and testing, voila! You’ve managed to assemble a set of rough but fairly accurate labels, and now you can train your model!
This is the promise of weak supervision. By detecting patterns and making observations, we can cut out dozens of hours of work and shortcut to the fun part of the ML workflow, all without compromising on good data.
Is That It?
You might now be wondering: “Okay, and what’s so special about that? That’s just getting the computer to guess at the rules. Why does that warrant the name ‘weak labeling’ or 'weak and all this buzz?” And I agree. When I was learning about this technique initially, I had two concerns myself:
- What if your labeling function results aren’t very accurate? Won’t that corrupt the model?
- What if your labeling functions are accurate enough on their own? Isn’t that enough for a classifier?
For the second concern, if your labeling functions are accurate enough on their own, that’s great! You’re already done. But as some research suggests, in general, you shouldn’t get your hopes up. The examples I showed earlier were generally clear, but there might also be more pathological examples in your dataset:
- “Abused her delicate youth with drugs or minerals” (Shakespearean)
- “Fans, take note! The #MedievalCavalry hath arrived.” (Slang)
For examples like these, blindly applying your weak labeling systems might lead to problematic results, where developing a model might yield a classifier with much better generalization. This leads us to point 1: what if our function results are insufficiently accurate for developing a good classifier? Messy data leads to a messy model. But this is why weak supervision isn’t just labeling functions—it’s actually a bit smarter than that. Under the hood, weak supervision implementations will use the noisy, less accurate labeling functions to generate a probabilistic labeling model:
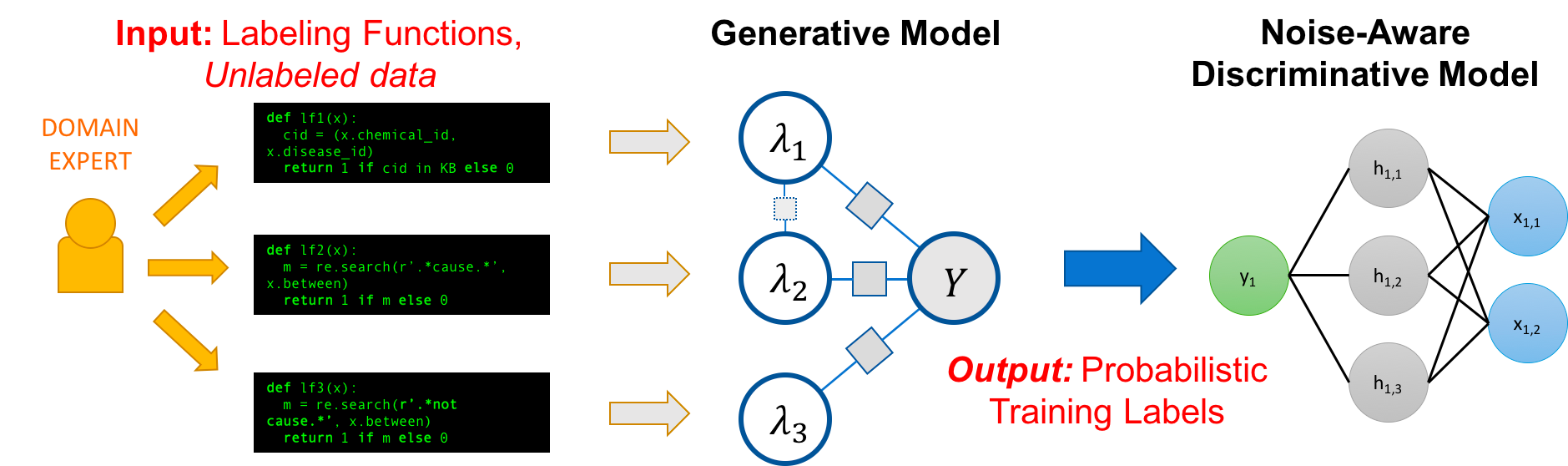
In this way, noise in the data is accounted for and the labels are adjusted accordingly, giving us more robust, accurate data that can then be used to train a classifier. With this, not only have you managed to assemble a dataset of thousands of points in just a few hours, you can train a model on your data with confidence, and effortlessly extend to even larger training datasets if the data is available. Congrats!
Weak Labelling and Work/Life Events at BetterUp
At BetterUp, we believe in helping people everywhere lead their lives with greater clarity, purpose, and passion. In order to help others move forward, we first have to know what might be holding them back. Because when we know what they’re currently struggling with, we can be so much more effective at helping—whether it’s through a coach recommendation or another on-platform experience. This brings us to the concept of work/life events, or WLEs—an idea developed by BetterUp’s “Human Insights Squad”, that makes rigorous the idea of occurrences of significance that take place in members’ lives.
A work or life event is an occurrence of significance to a person that causes a deviation from the norm in the given context, which can be related to work or life, and represents a change from the neutral in a person’s mood. Events are points in life that people spend time thinking about, and can often be a source of excitement, anxiety, or adaptation.
WLEs are important because they are the things our members spend significant cognitive and emotional energy on. They’re the kind of concepts that people might contemplate as being “the current big thing” in their lives, be those promotions, or big company changes, or marriages, or work conflicts. All in all, there were over 30 different kinds of events we wanted to classify from across a couple of sources of open-ended text.
Every day, thousands of BetterUp coaches and members get together for coaching sessions and work through various events and challenges that have occurred in members' lives. After these sessions have concluded, members and coaches are given the option to jot down a little bit about what was discussed in the session, and if the necessary consent requirements have been met, this data can be used to personalize their product experience. For example, a member might want to track how their work and life events impact their progress on their coaching journey, or a coach might be interested in keeping track of the key work and life events their members experience, in order to better prepare and provide the best coaching they can. We were able to sample nearly half a million sentences containing work and life events to train a specialized Work and Life event classification model.
Labels? Check. Data? Check. Time to put them together. For our weak labeling setup, we leveraged Humanloop’s Programmatic, a Python-integrated app for rapidly building large weakly-supervised datasets (they also have an excellent quick start guide for those interested!). Alongside weak labeling capabilities, it features a clean user interface and intuitive integration with Python and spaCy, making it perfect for turning our massive corpus into a labeled dataset in hours.
As for the labeling functions themselves, while the task of creating them was hardly trivial, it was relatively easy to find exploitable patterns in the data, and intensely reassuring to know that the power of weak labeling would be able to clean up any of the messes we may have made. For the purposes of this blog, I want to highlight three different logical paths we considered, which are reflected in our function statements.
Type A: Text and Regular Expression Matching
The easiest and fastest way we found to look for Work/Life Events, which simply involved matching text. These functions typically resemble one of these forms:
import re
def exact_words_matching(row) -> bool:
search_term = "career transition"
return row.text.find(search_term) != -1 # Match text exactly
def work_stress(row) -> bool:
# Use regular expressions to capture characters around words
# or to do case-insensitive matching, or capture multiple cases
pat = re.compile(r"\b(work(load)? stress|stress from work)\b", flags=re.IGNORECASE)
return pat.search(row.text) is not None
Functions like these work best when there are common phrases that have very consistent forms across mentions, which works for topics that have specific names or wordings (career transitions, performance improvement plans, relocations). But some topics can be a little more open-ended.
Type B: Start-and-End Phrase Matching
Consider the following set of sentences:
- “I’m considering moving to California for my work.”
- “An opportunity has opened up, but it requires me to relocate to Europe.”
- “Due to some family matters, my wife and I will need to move out South.”
All of these sentences are discussing the issue of moving, but all three do so in different ways, featuring different combinations of [move verb] and [relocation area]. Due to combinatorial explosion, there are too many combinations for us to track using brute-force pattern matching methods, so we need to try an alternate approach. This is the motivation behind our second type of labeling functions:
def find_move_phrase(row) -> bool:
"""
Find instances of end search phrases, then work back from there to find
the closest phrase from a list of candidate phrases and return true or false
if the phrase is found.
"""
start_search_phrases = ["moving", "relocating", "move", "relocate", "moved", "relocated"]
end_search_patterns = [
"city", "state", "country", "town", "district"
"[Nn]orth [Aa]merica", r"\bUSA?\b", "[Cc]anada",
r"\bCA\b", r"\bNY\b", "[Nn]ew [Yy]ork", r"\bTX\b", r"\bFL\b", r"\bLA\b",
r"\bSF\b", "[Bb]ay [Aa]rea", "coast", "region"
]
# If I put parens around the expression, split will give me the separators
# This is useful because I want to calculate separator lengths
end_search_phrases = [re.compile(f"({s})") for s in end_search_patterns]
max_chars_inbetween = 30
for end_search_phrase in end_search_phrases:
sections = end_search_phrase.split(row.text)
if len(sections) == 1:
continue
end = 0
for i in range(0, len(sections[:-2]), 2):
start = None
for start_phrase in start_search_phrases:
rfind_index = sections[i].rfind(start_phrase)
if rfind_index != -1:
start_phrase_index = rfind_index + len(start_phrase)
if start is None or start_phrase_index > start:
start = start_phrase_index
if start is not None:
start += end
end += len(sections[i])
if end > start and end - start < max_chars_inbetween:
return True
end += len(sections[i + 1])
else:
end += len(sections[i])
end += len(sections[i + 1])
return False
This function is a bit of an eyesore, but it implements the idea discussed above. For every specific ending pattern in the internally-defined list, the function will search backwards from their locations to try and find one of the starting words, returning True if a starting phrase is detected with a set hardcoded length limit (in this case, 30 characters). Here we assembled lists of [move verbs] and [relocation areas], but this idea works for any instance requiring start and end words. As an additional bonus, it can be easily modified to exclude certain keywords contained between the start and end words, if that functionality is desirable.
Type C: spaCy
The functions we’ve looked at so far are nice, but they’re language-agnostic. They don’t treat English words as having any special meaning, but rather focus on patterns between characters, entirely disregarding any additional information that could be obtained by treating words and sentences as linguistic objects. Of course, teaching Python the entirety of English would be incredibly difficult—not to mention that if we could do that, it would solve all of our problems instantly. But we can get pretty close using the spaCy NLP Library.
def verb_meeting(row: Datapoint) -> List[Span]:
"""
Use a spaCy Matcher object to find maximal instances
of given patterns
"""
matcher = Matcher(nlp.vocab)
phrase1 = [
{"LEMMA": {"IN": ["have", "prepare", "debrief", "join", "lead", "participate", "plan", "rehearse", "practice"]}},
{"POS": "ADP", "OP": "?"},
{"POS": "DET", "OP": "?"},
{"POS": "PRON", "OP": "?"},
{"POS": "ADV", "OP": "?"},
{"POS": "ADJ", "OP": "?"},
{"LEMMA": {"IN": ["meeting", "presentation"]}}
]
patterns = [phrase1]
doc = row.doc
matcher.add("Matching", patterns)
matches = matcher(doc)
by_match_starts = {} # For keeping only longest match
for match_id, start, end in matches:
span = doc[start:end] # The matched span
if start in by_match_starts:
if len(span) > len(by_match_starts[start]):
by_match_starts[start] = span
else:
by_match_starts[start] = span
spans = [Span(start=span.start_char, end=span.end_char) for span in by_match_starts.values()]
return spans
If you’re familiar with linguistics or formal language theory, you might have heard of a concept called parse trees or syntax trees, which are a way to break down statements of words into tokens using grammar rules. spaCy is capable of this, and we can use this feature to match specific patterns of grammar objects (certain nouns, verbs, prepositions, etc.) to match sentences. For example, the above function matches mentions of participation in meetings/presentations.
Fifty-one labeling functions later, we had our dataset, and it was time to train. Facebook’s RoBERTa provides a state-of-the-art transformer architecture, and fine-tuning it to our dataset was a breeze with Hugging Face’s transformers API. The result was exactly the high-quality, gold-standard WLE classifier we were looking for. Mission accomplished.
Final Thoughts
In a world becoming increasingly dependent on bigger and bigger data, the issue of scale is becoming more prominent than ever. As a result, techniques like weak labeling are becoming increasingly important, as our ML tools evolve to keep up with the needs of such a data-driven society. We’ve seen incredible results from weak labeling, but we feel like there’s so much further we can go, so much more we can do to use these approaches to help our members, and many more challenges waiting for us on the road to giving our customers the ultimate coaching experience.
About the Author
Colin He is a Machine Learning Engineer on BetterUp's Human Insights squad, and an undergraduate CS student at the University of Waterloo. He enjoys Nintendo games and videos about elegant math problems in his spare time, and is still running from a looming coffee addiction.
Join the conversation